
TLDR
Most businesses pick a voice AI vendor on three things. Price per minute, response latency, and how good the demo sounds. All three are the wrong thing to measure. The only metric that matters is whether the agent produces the business outcome you hired it for, like appointments booked or leads converted. Measure that, compare it to your human team, and you have your answer.
90% of Businesses Evaluate Voice AI Vendors on the Wrong Metrics
Around 90% of businesses evaluate voice AI vendors on metrics that tell them nothing about whether the agent will earn its keep. A vendor can sell you an agent that costs 2 cents a minute and books zero appointments. Cheap is not ROI.
The latency pitch is just as hollow. A vendor can hand you 200ms response time and an agent that talks over your customers the whole call. Fast is not good. The demo is the worst offender, because a vendor can build one that sounds flawless and then watch it break the first week it hits real production traffic.
These three proxies dominate even the most serious technical guides. Braintrust's evaluation article is written for developers and centers on word error rate, p95 latency, and golden datasets. Hamming's QA framework opens with a four-layer stack that obsesses over time to first word and barge-in timing.
Both are sharp tools for the engineers who build agents. Neither asks the question a business buyer needs answered. How many appointments did it book, and was that more or fewer than your team would have? Hamming even coins the phrase "metric mirage" for dashboards crowded with technical numbers that still miss the failure. The fix it offers stays technical, when the real fix is to measure the outcome.
Price Per Minute Is a Trap
A vendor selling you voice AI at 2 cents a minute is selling you usage, not results. The math feels safe because you can compare it against your phone bill. It tells you nothing about whether the agent books a single appointment.
Think of pricing as a ladder. At the bottom sits usage, where you pay per minute or per call regardless of what happens. One rung up is outputs, paying per task completed. Higher still is outcomes, where you pay for a resolved conversation or a booked appointment. At the top is profit, where the vendor shares in the value created.
Most voice AI vendors price at the bottom rung because usage is easy to bill and easy to defend. Demand they sit higher.
A vendor willing to charge $0.99 per resolved conversation is telling you something. They believe the agent will resolve enough conversations to make that price worth it. Outcome-based pricing puts the vendor's revenue on the line next to your result, which is exactly the alignment you want when you sign.
Latency Doesn't Matter (As Much As You Think)
A vendor can hand you 200ms latency and a voice AI that still talks over your customers. Speed and conversation quality are different problems. An agent that responds instantly but barges in mid-sentence frustrates callers faster than one that pauses a beat and lets them finish.
Hamming's QA framework spends its entire Layer 1 on infrastructure targets like Time to First Word under 400ms and barge-in recovery within 200ms. Those numbers are real engineering, but Hamming itself coined the term "metric mirage" to describe dashboards full of green metrics that still miss the agent failing the caller. Fast turn latency tells you nothing about whether the agent booked the appointment.
Treat latency as a floor, not a differentiator. Once an agent responds quickly enough to feel like a conversation, shaving another 50ms changes nothing your customer notices. Every serious vendor clears that bar. Ask instead whether the agent finishes the job, and let latency stay where it belongs.
Demo Quality Tells You Nothing About Production
A demo is a controlled environment built to make the AI look good. The vendor picks the scenario, scripts the happy path, and runs it on a quiet line with a cooperative caller. Production sends angry customers, crosstalk, background noise, and questions nobody scripted.
The gap between demo and production is where most deployments die. A LangChain survey found 52% of teams have deployed AI agents in production, but 32% name output quality as their top barrier. More than half of the teams shipping these agents still cannot trust how they perform once real calls hit them.
Developer tools recognize the problem. Braintrust builds golden datasets and offline evaluations, regression test sets covering known failures and edge cases, so engineers can catch breakage before it reaches a customer. Useful work, but it answers a developer's question, not yours. A passing test suite does not tell you whether the agent booked more appointments than your front desk did last month.
The Right Framework: Evaluate AI Like You Evaluate People
You hired a human agent to book appointments. You judged that agent on how many appointments they booked, not on how quickly they spoke or how charming they sounded in the interview. Apply the same standard to a voice AI vendor.
Pick the one outcome your business actually pays for. Appointments booked. Leads converted. Calls resolved without a human. Then measure the AI against that number, and compare it to what your human team produces today. An agent that books 40 appointments a week is working. An agent that sounds human and books 12 is not.
Use real benchmarks to set expectations. Fin AI's data shows a 67% average resolution rate across customer service deployments, with top performers hitting 80 to 84%. That gives you a concrete reference point. If a vendor cannot tell you where their agent lands against numbers like these, they have not measured it.
No single metric carries the verdict. Microsoft's research on conversational AI found that composite scoring across multiple dimensions beats any one number, because outcomes depend on accuracy, containment, and customer behavior together. Resolution rate alone hides whether customers came back frustrated. Treat the outcome as a multi-dimensional view, not a single line on a slide. Then you will know whether the AI earns its seat the same way a person would.
Wrong Metrics vs. Right Metrics
Put the two lists side by side and the problem becomes obvious. The left column is what vendors put on a slide. The right column is what shows up in your bank account.
Every metric on the left can look excellent while the agent books nothing. The right column ties straight to revenue, which is the only column your business feels.
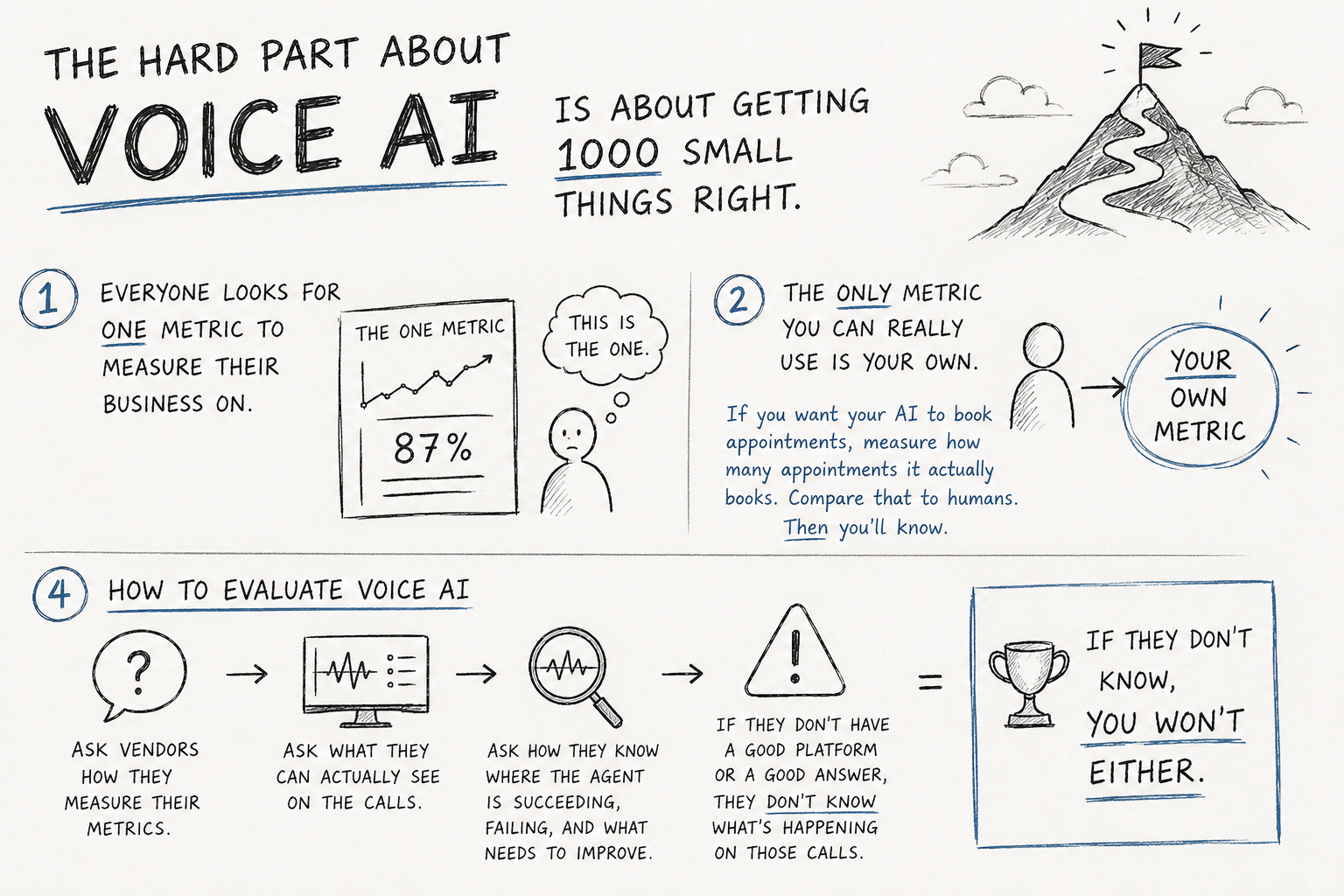
The One Question to Ask Any Voice AI Vendor
Ask every vendor one question. "How do you measure performance, and can you show me in your platform where I'd measure mine?" Then watch what they do.
A good answer pulls up a native dashboard. The vendor shows you appointments booked, calls resolved, and where conversations failed, across every call. That is the bar. Traditional CSAT surveys reach only 5 to 15% of calls, so a platform that covers 100% of calls gives you a picture you can actually trust.
A bad answer dodges. The vendor talks about latency, plays you another demo, or promises to wire up a webhook to some external reporting tool you already pay for. That dodge tells you something specific. They do not know what is happening on their own calls.
The follow-on problem is yours. If the vendor cannot see outcomes on their calls, you will not see them on yours either. You will sign a contract, deploy the agent, and have no way to prove it books a single appointment.
What a Good Voice AI Analytics Platform Looks Like
A good analytics platform shows you every call, not a sample. Traditional CSAT surveys reach 5 to 15 percent of calls, which leaves the outcomes you care about invisible. Demand 100 percent call coverage so you can count how many appointments the agent actually booked across every conversation it handled.
The platform should track your business KPIs without making you write custom scorer prompts. Developer-first tools like Hamming and Braintrust ask QA engineers to define LLM evaluation prompts and wire webhooks into external systems. You should not need an engineering team to learn whether the agent converted leads last week.
A/B testing belongs inside the platform too. You want to run two prompt configurations, or two vendors, against live calls and compare the outcome each produces. A vendor confident in its results gives you that comparison instead of hiding behind a polished demo.
Phonely builds toward this standard. Its call analytics dashboard reports outcomes across all calls rather than a survey sample, and its A/B testing features let you compare configurations on the metric you hired the agent for. Ask any vendor to show you the same thing in their own platform before you sign.
The Buyer Checklist
Run any vendor through this list before you sign. If a vendor stalls on more than two of these, walk.
- Define the one outcome you're buying. Appointments booked, leads converted, calls resolved. Pick one.
- Make the vendor demo their analytics platform live, not a slide deck.
- Confirm 100% call coverage, not a 5-15% CSAT survey sample.
- Ask whether you can A/B test configurations and measure which one books more.
- Treat outcome-based pricing as a positive signal. Per-minute pricing rewards usage, not results.
- Get two or three production reference customers in your industry.
- Agree on a baseline comparison method before launch. Measure the AI against your human team.
- Check that the platform shows escalation and containment rates per call.
- Ask how the vendor measures their own performance, then verify you can see yours.
- Walk away if they can't show you what happens on the call.
Conclusion
Price per minute, latency, and demo polish tell you almost nothing about whether a voice AI agent will book appointments, convert leads, or resolve calls. The only honest test is whether the agent produces the outcome you hired it for, measured against your human team. Cheap minutes and a smooth demo are not results.
Ask every vendor the same question before you sign anything. "How do you measure performance, and can you show me in your platform where I'd measure mine?" If they cannot show you a dashboard with full call coverage and your business KPIs, they do not know what is happening on those calls, and you will not either. Phonely builds for that question first.
Frequently Asked Questions
What is the best way to evaluate voice AI for business? Measure the business outcome you hired the agent to produce, like appointments booked or calls resolved. Phonely tracks these outcomes natively rather than burying them under technical proxies. You learn whether the agent earns its cost before you commit.
What metrics should I ask a voice AI vendor to show me? Ask for resolution rate, conversion rate, and cost per outcome, not word error rate or average latency. Phonely surfaces these in its call analytics dashboard across 100% of calls. That coverage beats traditional CSAT surveys, which sample only 5 to 15% of conversations.
How do I know if a voice AI agent is actually working in production? Compare its outcome numbers against your human team baseline over real call volume. Phonely's A/B testing lets you run configurations side by side and read the difference in results. Production data, not a demo, settles the question.
What does outcome-based pricing mean in voice AI? The vendor charges per result, like a resolved conversation, instead of per minute. Phonely treats this pricing model as a confidence signal worth demanding. You pay for outcomes, so the vendor carries the risk of underperformance.
How does voice AI performance compare to human agents? Fin AI benchmark data shows a 67% average resolution rate, with top performers reaching 80 to 84%. Phonely gives you the numbers to run that comparison against your own staff. A clear baseline tells you whether to deploy, expand, or walk away.





